Przygotowanie zbioru wejściowego do treningu modelu segmentacji zdjęć termowizyjnych
Proces przygotowania zbioru danych do treningu modelu segmentacji zdjęć termowizyjnych jest kluczowym krokiem w projekcie TherMobEye. Obejmuje on kilka etapów, od ręcznego oznaczania obszarów na zdjęciach, przez augmentację danych, aż po podział danych na zestawy treningowe, testowe i walidacyjne. Poniżej przedstawiamy szczegółowy opis tego procesu.
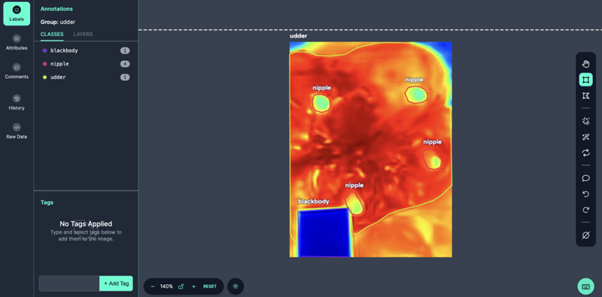
Oznaczanie zdjęć za pomocą platformy Roboflow
- Import zdjęć: Na początku zdjęcia termowizyjne są importowane na platformę Roboflow. Jest to narzędzie, które umożliwia łatwe oznaczanie i przygotowanie danych do treningu modeli uczenia maszynowego.
- Ręczne oznaczanie obszarów: Zdjęcia są ręcznie oznaczane za pomocą narzędzia Polygon dostępnego na Roboflow. Oznaczamy trzy główne obszary:
- Blackbody: Ciało referencyjne używane do kalibracji temperatury.
- Nipple: Sutki wymienia.
- Udder: Cały obszar wymienia.
- Dokładność oznaczania: Każdy z tych obszarów jest starannie oznaczany, aby zapewnić najwyższą dokładność modelu segmentacji. Proces ten jest wykonywany ręcznie przez ekspertów, co gwarantuje precyzję.
Augmentacja danych
Po oznaczeniu zdjęć, są one poddawane procesowi augmentacji, który polega na tworzeniu dodatkowych wariantów istniejących zdjęć poprzez wprowadzenie różnorodnych transformacji. Augmentacja jest kluczowa, ponieważ zwiększa różnorodność danych treningowych, co pomaga modelowi nauczyć się lepiej generalizować.
- Rotacje: Zdjęcia są obracane o 90° w kierunku zgodnym z ruchem wskazówek zegara, przeciwnym do ruchu wskazówek zegara oraz do góry nogami.
- Skalowanie i przesunięcia: Zdjęcia są skalowane i przesuwane, aby symulować różne odległości i pozycje aparatu.
- Zmiany jasności i kontrastu: Modyfikacje te pomagają modelowi radzić sobie z różnymi warunkami oświetleniowymi.
- Zakłócenia i szumy: Dodawanie szumów do zdjęć pomaga modelowi nauczyć się ignorować nieistotne zakłócenia.

Podział danych na zestawy
Aby zapewnić rzetelną ocenę wydajności modelu, dane są podzielone na trzy zestawy:
- Zestaw treningowy (70%): Używany do trenowania modelu. Jest to największy zestaw danych, który pozwala modelowi nauczyć się rozpoznawać wzorce w danych.
- Zestaw testowy (20%): Używany do oceny wydajności modelu po zakończeniu treningu. Dane testowe nie są używane podczas trenowania modelu, co zapewnia uczciwą ocenę jego wydajności.
- Zestaw walidacyjny (10%): Używany podczas trenowania modelu do monitorowania jego wydajności i dostrajania hiperparametrów. Pomaga to w zapobieganiu przetrenowaniu modelu.
Przygotowanie danych do treningu
- Eksport danych: Po oznaczeniu i augmentacji, dane są eksportowane z Roboflow w formacie kompatybilnym z frameworkiem YOLOv8.
- Konfiguracja plików: Pliki konfiguracyjne są tworzone, aby określić ścieżki do obrazów i etykiet, a także inne parametry potrzebne do treningu modelu.
- Trening modelu: Model YOLOv8 jest trenowany na przygotowanych danych, wykorzystując zestaw treningowy do nauki i zestaw walidacyjny do monitorowania jego wydajności.
Podsumowanie
Przygotowanie zbioru danych do treningu modelu segmentacji jest kluczowym etapem, który wymaga precyzji i uwagi na szczegóły. Od ręcznego oznaczania zdjęć, przez augmentację danych, aż po podział na zestawy treningowe, testowe i walidacyjne – każdy krok jest istotny dla zapewnienia, że model będzie mógł skutecznie uczyć się i generalizować na nowych danych. Dzięki wykorzystaniu platformy Roboflow oraz odpowiednich technik augmentacji i podziału danych, proces ten jest zoptymalizowany pod kątem uzyskania jak najlepszych wyników.